Paper Notes - Json Tiles

This paper introduces an approach to handling JSON data that enables big performance gains over traditional approaches in a large fraction of practical situations.
The Big Idea(s)
The paper leans into the following ideas:
- JSON is ubiquitous at the application layer. It is passed around all the time, and used for various purposes.
- If you could efficiently store/query this data, that would greatly simplify both app development and the analytics story for developers (aka it would be valuable for businesses).
- Existing RDBMS approaches to storing JSON are extremely inefficient for querying (typically stored as a single continuous string/binary blob in a field). This is true for both OLTP and OLAP queries. In the OLTP case, JSON data being stored as a blob makes join optimizations not work nearly as well. In the OLAP case, the row-oriented nature of most RDBMSes combined with the need to parse the entire JSON blob from its field to extract a single value, means that OLAP queries are horribly inefficient compared with columnar databases with defined schemas.
- People have hesitated to store JSON as anything other than a single-continuous blob because the theoretical complexity of a JSON object is very high. JSON is semi-structured, and its that flexibility that makes it difficult for RDBMSes to do anything other than store it as a binary blob.
- While the theoretical complexity of a json blob is high, in practice, JSON data received in a given column is extremely likely to have a reliable, implicit schema that evolves over time but is mostly stable and often changes in backwards compatible ways.
- You can derive this implicit schema by inspecting the received json blobs for a given table.
- You can use this derived schema to store the JSON blobs in a way that is much more optimized for OLTP or OLAP use cases. A big win.
So, by being a little bit clever with handling JSON data, you can get huge performance improvements for analytics use-cases compared with existing standard approaches.
Overall, the big ideas come back to the main big idea in almost all of these scale/efficiency-focused papers: identify things that are expensive in the current system (e.g. processing entire json blobs to read a single value), and figure out how to use the cheaper parts to do that same thing better (one-time analysis of json to find structure, store/query using that structure).
Reflections While Reading
- It seems like the experience that the author has/expects around JSON documents in real-world applications is noticeably different from my own experience. Specifically, the authors seem to expect that JSON blobs being stored in DBs are these positively massive documents with large numbers of keys and nested structure. My experience is fairly different. While nested structure is fairly common, I rarely encounter JSON nested more than 3 levels deep. And probably the majority of JSON structures that I have encountered professionally as a mobile developer/in side projects are less than 100 keys total. The result of this difference is that I am extremely optimistic about using this kind of approach to derive schemas on the fly in the vast majority of relevant cases.
- I’m envisioning a system where you expose an API on top of this system, backed by duckdb, where a given path corresponds to a specific table/type of json object and you don’t have to do any schema setup at all, you just boot up this process and start piping it data and have the ability to run efficient analytics queries on the other side. I’m less confident in using it for OLTP use-cases, as those seem much more latency sensitive, as a general rule. But being able to get efficient/reasonable analytics by sending JSON blobs without any schema setup seems like quite a big win for me as a solo developer of side projects.
- I wonder how far you can take the analysis of the json documents. My original intuition is that you would have a single table that is materialized from a given collection of (related) JSON blobs. But I wonder if you could derive relations and thus join tables from looking at document structure. Presumably you could do this.
- I found this figure to be helpful in visualizing how JSON Tiles transform input data into materialized columns in a DB:
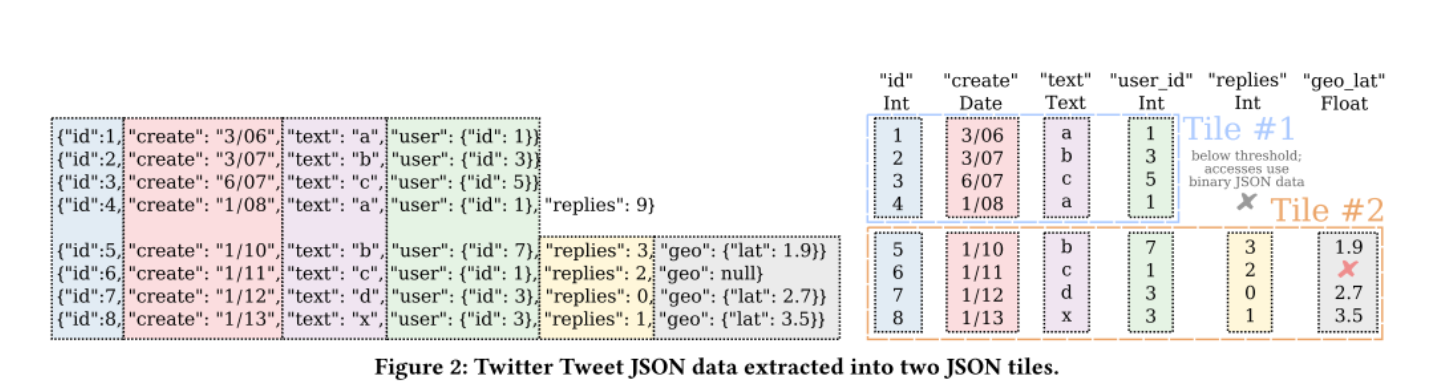
- The section on “reordering” tiles was pretty interesting. It, again, highlights a use-case that is a little strange to me, but is plausibly how many systems work. It considers a stream of json data with somewhat related, but not identical types (e.g. a news app logging json blobs about “publishing a story”, “publishing a poll”, “receiving a comment”, etc). Each of the json types received go into the same stream. The challenge then is that different types can have quite different fields, so the JSON tiles analysis of common fields would fail to find “common” fields because of the mixing of different types of data. To try and put is more explicitly, if you have 4 different types of data (1, 2, 3, 4), and each tile contains one blob of each type (tile = [1, 2, 3, 4]), you would run into a scenario where keys you care about (e.g. keys always present in Type 1 blobs) are only present in 25% of the blobs of any given tile (e.g. keys_present_in_tile = [{‘a’}, {‘b’}, {‘c’},
{‘d’}]). We see each key is only present in 25% of the blobs. That wouldn’t be high enough to materialize these keys into the resulting schema. But if you reorder the blobs within a set of tiles to intelligently cluster the blobs with similar shapes together (reordered_tile = [1, 1, 1, 2]), you can determine, with much higher accuracy, the proper keys to materialize (keys becomes [{‘a’}, {‘a’}, {‘a’}, {‘b’}], and we can “see” that ‘a’ is a common key whose data should be stored in columnar format). Smart! With that said, part of me feels like this is a pretty simple routing problem. We already have semi-structured json data. Is it too much to also include a name for the type when we send it to our systems? This could be a specifically named field (e.g. “type”), or in class-based/strongly-typed systems the programmer can pretty easily get the name of the class and send that along. Like, instead of sending the blob to a general
/analytics_eventendpoint, it shouldn’t be too hard to send it to/analytics_event/some_namefor the proper value ofsome_name. The reordering algorithm seems like a smart way to group together related blobs from a stream that contains many blob types. And also it seems like separating the stream by types should be easy enough to implement on the application programmer level.
- Reading more into the paper, I’m struck by how much of the work/design here is downstream of 1) committing to JSON as an object format and 2) not sharing the schema at all with the storage engine. Relaxing either of those constraints would likely lead to very different systems.
- There are lots of technical details about how to integrate the high-level JSON Tiles concepts (e.g. determine common keys in your json data and materialize them into column-oriented data) into an actual DBMS with efficient querying. I’m out of my depth in this area (e.g. what statistics would JSON tiles storage engine need to provide something like Postgres to allow for the query optimizer to make good decisions). With that said, the content makes some sense at a high level (e.g. you’d want to know how many items are present in a table when deciding what kind of join to run).
- It’s interesting to see the results of the performance testing. Looks like this materializing of columns does indeed offer significant performance wins over dumping JSON in Postgres/Mongo for analytic queries. Does look like 50-1000x speedups based on the queries run. Often you worry that these benchmarks are poorly constructed (e.g. basic optimizations are not done for the Postgres/Mongo DBs). I think that is certainly possible here, but hold out hope that the researchers, who are clearly experts in database performance, would construct reasonable benchmarks for comparison. In any case, here’s the table showing the results.
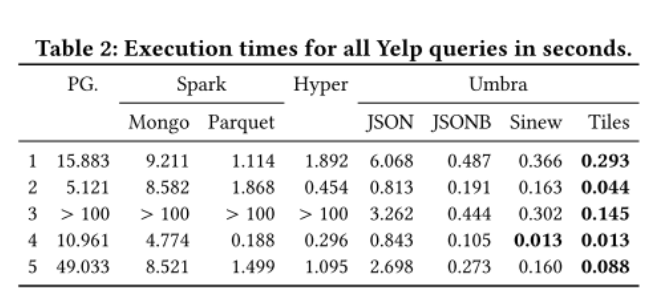
- Also, it looks like using JSONB types instead of JSON in a database is a very significant speedup for query performance. Good to remember.
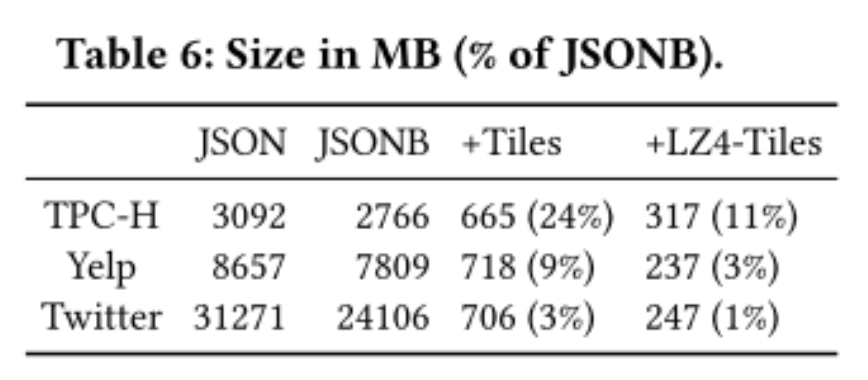
- The materialized columns take up extra space, and the JSONB raw data is still stored when using the JSON Tiles system because not all columns/data is materialized so some queries will have to fetch/parse the JSONB data. There’s an analysis that shows the extra space is pretty reasonable when using LZ4 compression. The amount depends ofc depends on what exactly is materialized and how amenable it is to compression. Probably best to share the table, which shows increases in storage size from 1-24% for adding in materialized columns.
Anki Notes
A collection of question/answer pairs that I put into Anki for review over time, in an effort to help me learn/retain this information over the long term.
How Do Relational DBs Typically Store Json Data?
As either:
- a single, continuous string
- a binary encoding of the entire json blob
As a result, when fetching a single field from the JSON object (common operation in analytics queries), you have to parse the entire blob. This is a lot of extra work to jest get a single field.
What Is the Key Idea Underlying Json Tiles That Speeds up Query Processing?
While JSON can theoretically have complex structure, in practice, JSON stored in DBs typically has highly predictable structure that can be analyzed on the fly. And when you understand the implicit structure, you can use that to store data in a way that speeds up query processing.

What Is a Json Tile?
A subset of JSON blobs from a larger collection, analyzed together to determine underlying implicit schema in broader data
In the image below, 8 json blobs are split into two tiles with 4 blobs per tile. Each tile is analyzed and a resulting schema is determined on the right side of the figure:
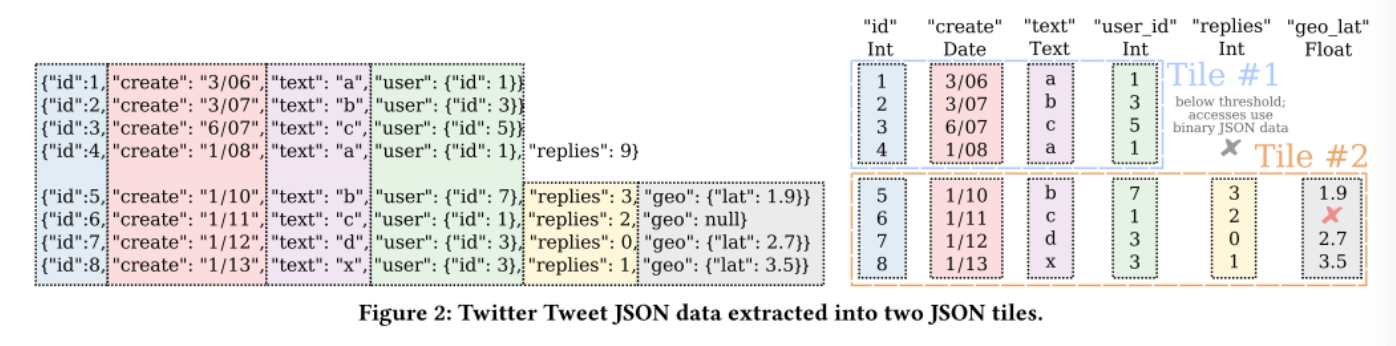
How Many Blobs/Tuples Typically Go Into a Single Tile?
The paper recommends 2^10-2-^12 blobs/tuples per tile. The number is selected to ensure good accuracy in determining common keys in the implicit schema of the received data.

When Blobs With Different Types Are Received, How Does the Json Tiles Algorithm Ensure That Keys Common to Each Type Are Identified As Important?
It reorders how blobs are placed in tiles so that blobs with similar types are clustered together in the tiles.
In the below figure, there are 12 tiles listed horizontallly by ID. The rows in the collection correspond to the blobs in each tile, and the pattern indicates what type each blob has. You can see, when scanning a tile vertically, that many tiles contain a general mix of blob types (aka vertically there are many patterns in each blob). After reordering, we see, again by scanning vertically, that the tiles now generally contain blobs of one or two types. Thus, the reordering brings blobs of the same type together into various tiles, making it easier to see the relevant implicit schema in each of the blob types.

Why Was It Important to Reorder the Json Objects Before Performing Schema Analysis on the Json Tiles?
Without reordering, you run the risk of tiles being filled with a variety of json blob types. The mix of types makes it hard to detect a consistent schema, which is the goal of the algorithm.
If the system fails to detect keys that are common in the json, the materialized columns will lack columns that should exist. And downstream of this, query performance will really suffer because when accessing those keys in the data, you’ll have to parse the entire json blob and do the extraction.
What Algorithm Is Used to Compute Itemsets?
FPGrowth

Here’s a link that talks about fpgrowth.
What Adjustment Is Made to the Fpgrowth Algorithm When Determining Itemsets for Json Blobs?
The JSON Tiles algorithm doesn’t compute full itemsets (as that has complexity proportional to the powerset of frequent items), but rather assigns a compute budget and runs fpgrowth until the budget is exhausted.

Note, this is highly reminiscent of a distributed systems talk I went to that built on this work, where the presenter talked about how they only recurse to a depth of 3 when identifying key paths in json blobs.
Why Does Json Tiles Store the Entire Json Object in Addition to Materialized Columns?
Because not all columns are materialized, so if a query asks about a non-materialized key, the system fetches and processes the information from the full object.
Remember, data for a key is only stored in columnar format if the system determines that the key/value is commonly present in the input data.
Does The Json Tiles System Use More Storage Space or Less Storage Space Compared With a System That Just Stores Json Objects in a Binary Format?
More. JSON Tiles materializes columns for common keys and stores the full JSON object in a binary format.
Why Is the Json Tiles System so Much Faster Than Postgres/Mongo/Existing DBs for Olap Queries Over Json Data?
JSON Tiles system extracts relevant data from the json objects and stores it in a columnar format. This provides two main performance benefits 1) for queries about extracted columns there is no need to parse the entire JSON object (a limitation of Postgres/Mongo/existing systems) and 2) the columnar format allows for more efficient disk reads of data in those extracted columns.
If Your Dataset Fits in Memory, Would Json Tiles Be Useful for Processing Json Information?
No. JSON Tiles is targeted towards improving the performance of analytic queries which involve amounts of data that do not fit in memory. The work done by JSON Tiles would not be necessary/relevant and would be pure overhead if you could keep your data accessible in memory.
What Is the Expected Storage Overhead From Json Tiles Materializing Commonly Used Keys?
The paper presents stats showing that the storage overhead varies from 1-24% depending on the type of data stored and whether the tiles are compressed.
The figure below is from the paper, showing the increase in size in parentheses (x%) from using JSON Tiles:
